- Computer architecture: a quantitative approach
Computer architecture: a quantitative approach
ch 1 Fundamentals
- Internet of Things/Embedded Computers:缺乏量化基准
- Personal Mobile Device:soft real time(对实时性的要求),功耗优化
- Desktop Computing:性价比
- Servers:可用性,可拓展性,有效吞吐
- Warehouse:性价比,功耗
ch 2/B Memory Hierarchy Design
基础知识
cache 基本配置有
block 可放置位置
- direct mapped:直接映射,$(Block\ Address)\mod(Number\ of\ blocks)$
- fully associative:全相联,cache 中任意位置
- set associative:组相联,在对应组中的任意位置,$(Block\ Address)\mod(Number\ of\ sets)$
替换算法
- random:效果不差,但是缺乏确定性,对程序优化不友好
- FIFO:first-in-first-out,可能导致抖动
- LRU:Least recently used,较优,但算法复杂,一般采用简化版,如 clock 算法
写策略
- 写命中 cache 时候
- write through:写穿透,cache 和底层都写,保持一致性容易
- write back:写回,只写 cache,之后 cache 写回底层,性能较好
- 写不命中时候,常常使用
write buffer减少写带来的 stall- write allocate:写分配
- No-write allocate:写不分配
- 写命中 cache 时候
cache 性能优化
优化目标为平均访问时间,有
$$ \mathrm{Average\ memory\ access\ time}=\mathrm{Hit\ time} + \mathrm{Miss\ rate}\times \mathrm{Miss\ penalty} $$
当中,可以把 miss 分类有
- compulsory miss:第一次访存必然 miss
- capacity miss:cache 容量有限,一些 block 被丢弃后再被访问
- conflict miss:cache 不是全相联,set 满而部分 block 被丢弃后再被访问
- coherence miss:多核时候,其他核修改导致数据过时而失效
简单优化有
- 增大 block ,减少 miss rate
- 利用 spacial locality:空间局部性,可以减少 compulsory miss
- 可能增大 miss penalty
- 在 cache 大小固定时候,过大的 block 大小会增加 conflict miss
- 增大 cache ,减少 miss rate
- 可能增加 hit time
- 可能增加成本和功耗
- 增加关联度
- 比较电路设计麻烦,可能提高 hit time
- 8-way 组相联和全相联一般表现类似
2:1 cache rule of thumb
大小 N 的 direct mapped 和$\frac{N}{2}$的 2-way set associative 一般 miss rate 相似(经验公式)
- 可能增加 hit time,高关联性会要求更低的时钟频率
- 多级 cache
- multilevel inclusion/ multilevel exclusion
- 平衡 fast hit 和 few misses
- read miss 优先于 write miss, 减少 miss penalty
- read miss 一般和取指,取数计算有关,优先可以减少程序的 stall
- 写缓存可能导致数据不一致,等写回内存用时过长
- 在 cache 内索引时避开地址翻译, 降低 hit time
- VIVT 对于保护,重名不利
- VIPT 需要如 page coloring 页着色等消除重名/使用 PID 进程号来记录 cache 对应关系
- 加大相联度,强行保证无需地址翻译
- 对于 L2 以下的 cache 不重要,因为访问 L2 时候必然已经经过了地址翻译
复杂优化有
- 简单的 L1 缓存, 减少 hit time 和功耗
- 为了更高的时钟频率和功耗限制
- 高相联性有助于不加大尺寸提高性能,但会提高功耗
- 处理器本身 cache 访问慢
- 为了不地址翻译,cache 大小受限于页大小
- 多线程程序容易引发 conflict miss
- 加大 block 大小减少行数以减少索引能耗,但会提高 miss rate
- 组织 banks, 分块激活
- 预测组相联的具体 way,加速访问速度,降低 conflict miss
- I-cache 更容易被预测
- way-selection:使用预测结果决定实际 cache 访问,适用于低功耗
- 流水线化缓存访问,多 banks 独立
- 流水线可提高 L1 时钟频率,会增加延迟,一般针对 I-cache
- 多 banks 独立针对,对于下级缓存,可以同时处理多个上级缓存缺失
- nonblocking cache, 提高带宽
hit under miss 允许乱序执行规避 stall
- 乱序执行刻意部分掩盖高层次的 cache miss,但对于高延迟的低层 miss 无效
Miss Status Handling Registers(MSHRs)记录缓存 miss 信息,一对一处理
- 关键词优先,更快重启
- cache line 比起一次 cache miss 要求的 word 更大,因此只要需要的数据可用,立即返回
- 融合写缓存
- 写相近地址的多字比多次写一个字快速
- 内存映射的 IO 不能写融合
- 编译器优化
- 循环展开
- blocking 访问
- 硬件预取
- 注意预取可能会遇到虚拟内存缺页、权限错误等问题
- 可能取来无用数据而影响功耗,在高负载下影响性能
- 编译器控制预取
- 不能干扰程序执行(比如 register perfetch)
- HBM:high bandwidth memory
- 大的 L4 缓存:
- 大 block:内部碎片,使用 subblocking 只激活一部分缓解
- tag 存储开销大:tag 和数据放在 HBM 同一行中,使用 memory 的行缓存加速访问
- 大的 L4 缓存:
虚拟存储
- 保护,保护机制在 page 上
- 共享,如系统库
- 管理内存使用和硬盘的 swap
| Page | Segment | |
|---|---|---|
| Words per address | One | Two (segment and offset) |
| Programmer visible? | Invisible to application programmer | May be visible to application programmer |
| Replacing a block | Trivial (all blocks are the same size) | Difficult (must find contiguous, variable-size, unused portion of main memory) |
| Memory use | inefficiency Internal fragmentation (unused portion of page) | External fragmentation (unused pieces of main memory) |
| Efficient disk traffic | Yes (adjust page size to balance access time and transfer time) | Not always (small segments may transfer just a few bytes) |
Translation Look Aside buffer
TLB,快表,作为页表的缓存
| bit | usage |
|---|---|
| Presence | page is present in memory |
| Read/write | whether page is read-only or read-write |
| User/supervisor | whether a user can access the page or if it is limited to the upper three privilege levels |
| Dirty | if page has been modified |
| Accessed | if page has been read or written since the bit was last cleared |
| Page size | whether the last level is for 4 KiB pages or 4 MiB pages; if it’s the latter, then the Opteron only uses three instead of four levels of pages |
| No execute | Not found in the 80386 protection scheme, this bit was added to prevent code from executing in some pages |
| Page level cache disable | whether the page can be cached or not |
| Page level write through | whether the page allows write back or write through for data caches |
virtual machine
- 用虚拟机隔离 os
- 可能有 bug 的操作系统
- 云用户
- 芯片性能足够开销
- 兼容和管理软件
- 管理硬件(可以跨越单台机器)
ISA 设计最好考虑虚拟机,virtualizable。保证特权指令在裸 os 和虚拟机的 os 下效果一致。也可以设计更多的特权级(RISCV 的 M、S、U 三态)。TLB 带进程号防止切换 os 频繁刷新。IO 设备也需要 vmm 来划分(如网络)和虚拟化(如硬盘)
shadow page table
减少 软件-os-vmm 2 次地址翻译开销,os-vmm 之间直接映射。需要 trap 所有的 os 对页表的改写
software guard extension
由进程定义的对内存的加密。上层 os 和 vmm 可以移动数据,不能解密数据
Fallacy
- 使用一个程序的访存推断其他程序。程序之间差异很大
Pitfall
- 地址空间太小
- 程序寻址空间大小$2^\text{address}$,太小的地址空间限制大程序
- 地址空间和
PC,寄存器等多方面相关,难以后期改变
- 忽略 os 对存储的性能影响,os 也会造成存储负载
- 依赖 os 智能调整页大小。os 一般只会针对如数据库和内存映射使用大页,os 不够智能
- 模拟指令来衡量访存性能
- cache 尺寸对于一小部分指令来说太大
- 程序不同阶段局部性不一样
- 程序对于不同输入局部性不一样
- 用 cache 但是内存带宽不够
- 在virtualizable有问题的 ISA 上设计虚拟机
- eg,80x86 的
POPF指令,在 user mode 下不改变IE;在 system mode 下改变。但POPF不是特权级指令,vmm 无法 trap 来保证虚拟化
- eg,80x86 的
ch 3/C Instruction-Level Parallelism and Its Exploitation
主要关注的是 basic block(只在代码块出入口有跳转,平均几行规模)和多个 basic block 级别的并行性。程序天然的存在依赖关系。优化需要保证依赖关系以保证正确的输出
- data dependence(RAW)
- 前一条指令的结果是后一条指令的输入
- 有传递性
- 存在于内存的 data depedence 比起寄存器之间的更难检测
- name dependence,在指令使用相同的寄存器(一般靠寄存器重命名消除)/内存地址(称为 name)时候出现
- antidepedence:前一条指令写后一条指令的读(WAR)
- output dependence:两条指令同时写一个寄存器/内存地址(WAW)
- control depedence:指令的执行条件不能被更改,不一定会被完美保持,而是保持能维护正确性的重要的 dependence
- exception behavior:保证修改指令序列不会导致异常的行为变动(eg,发生本来没有的异常)
- data flow:保证指令的数据来自正确的前面的指令,即使可能有多条指令和其有潜在的 data dependence(eg,正确选择来自某个分支的结果)
如果有依赖关系的指令距离很近,导致不能并行/重叠执行等,就会造成 hazard 使得处理器必须特别处理
- structural hazard:功能部件不能满足同时访问
- data hazard:数据依赖(按照正确执行应该保持的顺序来命名)
- Read After Write:RAW,真相关
- Write After Read:WAR,只有乱序时候出现
- Write After Write:WAW,只有乱序时候出现
- control hazard:跳转和其他改变
pc的指令
编译器优化 ILP
- 对于指针和引用,编译期的依赖关系难以检测
- 硬件预测一般能保证精确异常
- 有些程序的静态预测分支效果很差(整数控制程序,如数据库)
- 硬件预测不需要使用额外代码而增加代码体积
- 编译器可以调度更大范围内的依赖关系
- 硬件预测不需要对不同处理器架构针对性优化
- 硬件预测会导致复杂的控制逻辑,更多晶体管面积和能耗
循环展开
loop unrolling。减少循环判断次数,一个循环体里执行原先多个循环的内容。如果是未知的需要迭代$n$次,展开尺寸$k$,那么需要$\frac{n}{k}$次循环展开,$n\mod k$次原本的循环
- 减少判断和跳转的指令数目,以及其潜在的延迟
- 在更大的循环体里调度指令消除 data hazard 更容易
- 尽量用不同寄存器防止 name dependence
- 更改
load,store顺序来遮盖访存延迟
- 会增加代码体积;过度展开会导致 cache 性能差;通用寄存器数目有限,展开次数有上限
5 级流水
| 全称 | 简称 | 效果 | 伪代码 |
|---|---|---|---|
| instruction fetch cycle | IF | 按照pc取指令,并pc+=4 | IR<-Mem[PC],NPC<-PC+4 |
| instruction decode/register fetch cycle | ID | 指令译码,符号拓展偏移值,预测pc跳转地址,读寄存器(RISCV 的寄存器和立即数位置固定,可以在不在意功耗场合默认读取) | A<-Regs[rs1],B<-Regs[rs2], Imm<-sign-extended immediate field of IR; |
| execution/effective address cycle | EX | 1. 内存访问:ALU 计算基址+偏移 2. 寄存器-寄存器 ALU 3. 寄存器-立即数 ALU 4. 条件跳转:判断是否跳转。 对于 load-store 的 ISA(如 RISCV)执行和计算地址可以合并为一个周期 | ALUOutput<- A + Imm;ALUOutput<-A func B;ALUOutput<-A op Imm;ALUOutput<-NPC+(Imm<<2),Cond<-(A?=B) |
| memory access | MEM | 访存 | LMD<-Mem[ALUOutput] or Mem[ALUOutput]<-B;if(Cond)PC<-ALUOutput else PC<-NPC |
| write-back cycle | WB | 访存/ALU 运算结果写回寄存器文件 | Regs[rd]<-ALUOutput;Regs[rd]<-LMD |
有一些注意事项
- 分开 Icache 和 Dcache 保证一个 cycle 内取指和访存指令的访存不冲突
- 对于流水的 CPU,访存频率更高,要求更高的内存带宽
- 寄存器文件在 ID 时候需要 2 个读端口,WB 时候 1 个写端口
- 中间结果需要 pipeline registers 缓存下来,
IF/ID,ID/EX,EX/MEM,MEM/WB - 流水线的单一指令延迟会增加
- 最慢的阶段限制整体时钟频率
- pipeline register 读写和传播时间
流水线会遭遇 hazard 使得性能不如理论值。(暂停,清空等)
前递
forwarding,bypassing,short-circuiting。
把已经计算出来的被依赖的结果不等 WB 写回寄存器,直接传给需要的功能部件。
| 目标 pipeline register | 目标指令类型 | 源 Pipeline register | 源指令类型 | 前递位置 | 前递的条件 |
|---|---|---|---|---|---|
| EX/MEM | 寄存器-寄存器,立即数 | ID/EX | 寄存器-寄存器,立即数, load, store, branch | ALU 操作数 1 | EX/MEM.IR[rd] == ID/EX.IR[rs1] |
| EX/MEM | 寄存器-寄存器,立即数 | ID/EX | 寄存器-寄存器 | ALU 操作数 2 | EX/MEM.IR[rd] == ID/EX.IR[rs2] |
| MEM/WB | 寄存器-寄存器,立即数, Load | ID/EX | 寄存器-寄存器,立即数, load, store, branch | ALU 操作数 1 | MEM/WB.IR[rd] == ID/EX.IR[rs1] |
| MEM/WB | 寄存器-寄存器,立即数, Load | ID/EX | 寄存器-寄存器 | ALU 操作数 2 | MEM/WB.IR[rd] == ID/EX.IR[rs2] |
前递不是万能的。如果是上下两条指令之间依赖,需要比如在 ID 阶段暂停流水线。比如对于依赖 load 指令结果的 RAW 依赖,需要实现load interlock
| 需要 stall 的 IF/ID 指令类型 | 判断条件 |
|---|---|
| 寄存器-寄存器, load, store, 立即数, branch | ID/EX.IR[rd]== IF/ID.IR[rs1] |
| 寄存器-寄存器, branch | ID/EX.IR[rd]==IF/ID.IR[rs2] |
乱序
- 减轻对特定架构编译的依赖,二进制分发有效率
- 应对编译期未知的依赖
- 应对不可预计的停顿,如 cache miss
Scoreboard
CDC6600 开始采用的乱序执行机制。scoreboard 会记录和管理依赖关系。指令会首先顺序被 scoreboard issue(发射)。这套方法没有前递,因为是乱序执行,指令不需要等到自己的 WB 才能写进寄存器。但写寄存器和读之间还是需要 stall 一个周期。而且需要处理读写寄存器的总线的 structural hazards。
- issue:直到没有 structural hazard 和 WAW,功能部件空闲时候指令发射。暂停时候,指令队列可以接着取值
- read operands:没有指令会写 operands 时候读寄存器,这样动态解决 RAW
- excution:执行指令
- write result:直到没有 WAR 时候写完成的结果
Tomasulo
动态决定指令开始执行的时机以及寄存器重命名来消除 WAW、WAR。
register renaming
寄存器重命名。将目的寄存器重命名,避免乱序完成影响实际的操作数。既可以编译器实现(在逻辑寄存器充足时),也可以硬件实现(在物理寄存器多于逻辑寄存器时)
reservation stations
保留站。缓存指令的类型,操作数,结果等信息,有:
- Op:操作
- Qj,Qk:操作数来源的保留站号,为 0 表示操作数就绪/不需要
- Vj,Vk:操作数的值。对于
load指令,Vk 表示偏移- A:访存计算出来的地址
- Busy:表示保留站和对应功能部件占用中
对应的,寄存器文件有:
- Qi:表示结果来源的保留站号,如果为空/0,目前没有指令目标寄存器是自己
common data bus
CDB。在 360/91 上,允许多个部件同时读可用的操作数,以实现前递
- issue:从 FIFO 的指令队列里面,取第一条指令。这一步会完成寄存器重命名解决 WAW、WAR,有时该阶段被称为 dispatch
- 对应保留站空闲,发射指令
- 对应操作数就绪,读寄存器文件,否则追踪对应的功能部件,等结果
- 对应保留站忙碌,出现 structural hazard,stall 指令
- execute:等操作数以解决 RAW
- 如果操作数还不可用,一直监听 CDB 直到可用
- 可用时候上到功能部件执行
- 如果多条指令同时可以执行,任选一条
- 如果是访存指令,按照程序顺序执行,并且把地址传到 load/store buffer 里等访存部件可用
- 访存指令可以简化按照程序顺序计算访存地址,但
load之间是可以乱序的
- write result:在 CDB 上广播结果,写寄存器,如果是
store指令,把地址和值写到 store buffer 中,等访存部件可用
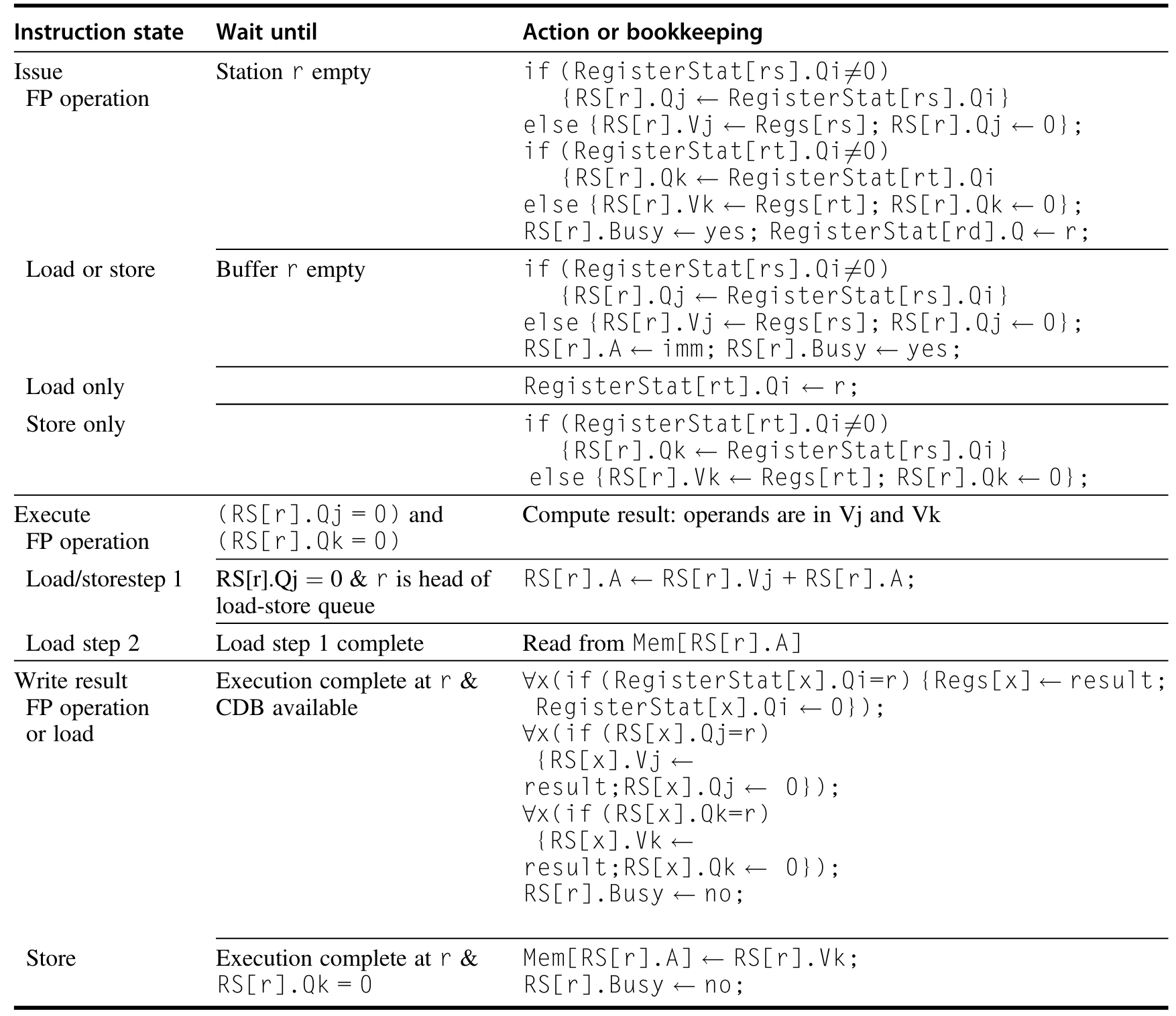
Tomasulo 模式需要高速的集成的 cache 来保存大量消息,需要复杂的控制逻辑,需要高速高带宽的 CDB(多条 CDB 能提高带宽,但一致性需要解决)。Tomasulo 模式适合于多级 cache 的体系结构,因为可以掩盖不可控的 cache 延迟。对于程序员和编译器优化更友好。
硬件预测
为了应对 control hazard,虽然有分支预测技术,分支指令过于频繁,或者是多发射处理器一次应对很多条指令,因此需要引入硬件预测。处理器执行犹如分支预测一直成功一样。
reorder buffer
ROB。在执行完成和 commit 之间缓存结果
- 指令类型
- 目标地址
- 值
- Ready
- issue:从指令队列有序发射,只要 ROB 和保留站空
- exectue:等 CDB 直到操作数全部就绪
- write result:把结果暂存进 ROB
- commit:有序提交
- 把结果写到寄存器文件
- 实际进行
store的访存 - 分支预测错误的 ROB 项清空

由于有序 commit,而改写寄存器和内存的值只在 commit 时候实现。因此可以保证只有在指令确定下来时候才实际更改机器状态。而且这也可以保证精确异常。而load的安全通过,1)在地址和某条 ROB 中地址重合时候不执行;2)按程序顺序计算访存地址来保证。
预测可能会导致出现本来不出现的异常和 cache miss。一般的,为了性能,预测阶段只会处理高级别 cache miss,其他的异常都等到指令确定性时候才触发。特别是比如权限的异常(不必要的终止,meltdown 漏洞等)。对于结构性较差的程序(比如数据库查询),预测执行可能会遇到大量嵌套的跳转。出于能耗和复杂度,一般不会对多分支多做优化。对于访存还可以通过 Address aliasing prediction,进一步发掘指令级并行度。
Address aliasing prediction
预测访存地址是否冲突,从而允许访存相对乱序执行。相对简单,可以用简单的预测器实现
value prediction
预测指令的结果,进一步消除数据流之间的限制关系。过于复杂,目前没有实用性
另一种方法是不使用 ROB,而是实际实现大量物理寄存器(对比 ISA 规定的逻辑寄存器,architectural register),使用 renaming map 管理寄存器重命名。只需要保证逻辑寄存器有关操作的正确,实际对应关系一直变动是不重要的。
多发射
| 名称 | 发射结构 | Hazard 检测 | 调度策略 | 特点 | 例子 |
|---|---|---|---|---|---|
| 静态超标量 | 动态 | 硬件检测 | 静态调度 | 顺序执行 | 嵌入式芯片,如 MIPS,ARM,包括 Cortex-A53 |
| 动态超标量 | 动态 | 硬件检测 | 动态调度 | 乱序执行,不带推断 | 现在不存在 |
| 推断超标量 | 动态 | 硬件检测 | 动态调度 | 带推断的乱序执行 | Intel Core i3, i5, i7; AMD Phenom;IBM Power |
| VLIW/LIW | 静态 | 主要靠软件 | 静态调度 | 靠编译器检测和隐式提示 hazard | 信号处理器,如 TI C6x |
| EPIC | 大多数静态 | 主要靠软件 | 大多数静态调度 | 靠编译器检测和显式提示 hazard | Itanium |
- 半周期发射指令。缺乏拓展性,只适用于双发射
- 在一个发射周期内,检查所有指令间的和与已发射指令的依赖关系。控制逻辑复杂
多发射的处理器需要更好的取指部件,保证指令来源不成为瓶颈。常见的对取指部件优化有:
- 在取指时候集成 分支预测
- 预取指令
- 提供取来的指令的缓存
VLIW
VLIW
very long instruction word。超长指令字。一条打包不同功能的指令
分支预测
在跳转指令到 EX 之前就猜测出跳转目标,就可以减少因为跳转带来的停顿。如果错误预测则需要清空流水线。
现实中的分支预测器极其影响性能。因此商业处理器的分支预测策略消息很少。
Branch-Target Buffer
缓存历史的分支指令 PC 和 taken 对应预测目标的 PC。减少 PC 计算,下个周期直接取分支部位指令。如果分支预测正确,可以完全不停顿
branch folding
对于无条件跳转,可以给 Branch-Target Buffer 加一位 bit 提示,这样不再需要预测
程序中存在跳转地址不固定的跳转指令,比如多处调用同一个函数,函数的返回地址就会变化。可以使用一个小的函数调用栈 cache,优化函数返回的跳转。
静态预测
使用编译期信息进行分支预测。不同程序对于 taken 的概率对 50%有明显的偏移
2-bit/n-bit
branch-prediction buffer/branch history table
低位指令地址+预测器,如最简单的 1-bit 是否选择分支
1-bit 的预测器可以扩展到 2-bit 状态机,防止偶发的 taken 变化造成 2 次错误预测。若为 n-bit,大于等于 $\frac{2^n-1}{2}$ 取 taken,反之 not taken。二者性能差异不大
| |
(m,n)预测器
$$\text{bits used}=2^m\times n \times \text{Number of prediction entries selected by the branch address}$$
一个 m 位移位寄存器记录全局历史,当前跳转的前 m 个实际分支行为历史,每一位用来记录该分支是否实际被执行,1 对应实际执行,0 对应实际未执行。 $2^m$ 的可能性分别对应 $2^m$ 个 n-bit 简单预测器。因此,2-bit 相当于(0,2)预测器
g-share 预测器
把分支历史和分支地址异或(类似于 hash 的功效)索引一个 2-bit 预测器
| |
Tournament(锦标赛)预测器
结合局部 local 和全局 global 的 2-bit 预测器,并使用 branch address 选择 local/global 预测器。注意,预测错误时需要同时更新选择器和预测器。
| |
Tagged Hybrid/TAGE 预测器
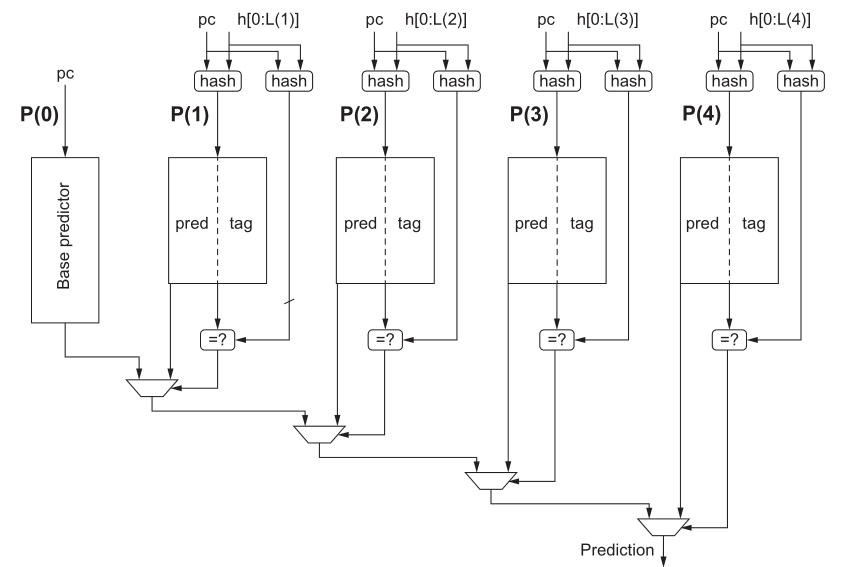
使用不同历史记录长度的预测器$P(0),P(1)$ 。$P(i)$ 使用PC的一部分和(用移位寄存器记录)的最近 i 条分支历史的 hash 结果索引,包括 2-bit 预测器(实际中 3-bit 更好一点)+ 4-8bit 的 tag。PC和 tag 比较($P(0)$不比较,作为默认使用预测器),决定使用本级的预测器还是上一级结果。
预测器可以包含一个 bit 用来表示该级是否最近使用过,并以此决定刷新频率。预测器内容的初始化有多种方式,而且对于短的程序,初始化的性能表现很重要。
- 随机初始化
- 使用 valid bit 标记尚未初始化的条目
- 使用指令自带的偏向的 hint 初始化(如果不做动态预测器,那处理器就会使用 hint 作为预测
- 向后跳转指令可能用于循环,因此初始化为 taken
多周期指令
比如浮点运算对比整数 ALU 运算慢很多。如果希望浮点指令运算和整数指令运算都能在一个周期内完成,需要极大降低频率而损害性能。一般有额外的浮点功能部件:
- 整数的 ALU,load,store,branch 功能部件
- 浮点数和整数乘法器
- 浮点加法器
- 浮点和整数除法器
多周期指令会带来额外的复杂度。可以通过分离整数寄存器和浮点数寄存器简化依赖检测(只有浮点数 load-store 和浮点寄存器移动可能出现依赖)和减少 structural hazard (端口自然分离)发生。
- structural hazard:
- 除法器不能完美流水化(额外除法器占晶体管资源)
- 多指令同时写回对寄存器文件写端口
- 在 ID 阶段检测冲突并引入 stall,保持只在 ID 检测 interlock 和停止发射指令
- 在进入 MEM、WB 之前暂停指令,一般选择长周期指令优先(减少可能的 RAW),检测冲突更容易,但是流水线控制不好做
- 多周期要求多种中间寄存器
- 不同周期指令之间执行用时不一而 WAW(WAR 不可能,因为只有在 ID 阶段才读寄存器,ID 阶段进入是有序的)
- 如果两条指令之间出现异常,连续写同一寄存器的 WAW 就会暴露出来。
- 可以 stall 顺序在后的指令
- 可以不执行前一条指令的写寄存器(注意精确异常的要求)
- 不同周期指令的 out-of-order completion 对于精确异常的要求
- 放弃精确异常/两种工作模式:早期机器和科学计算机器,但不符合 ieee 标准
- 缓存结果,有序提交(类似乱序处理器),可能空间占用大,而且前递复杂
- history file,记录历史值来回滚
- future file,记录新值来更新
- 不精确异常+回溯信息:异常恢复后模拟之前没完成指令的执行效果,适合简单处理器,整数指令一定执行完,只需考虑少数重叠的浮点指令
- stall 直到肯定不出现不精确的异常
- 长延迟对 RAW 有影响
中断/异常
precise exception
精确异常:异常之前的指令都生效,异常之后的指令都没生效(执行到一半就要回滚已经产生的影响)
精确异常符合程序员和编程语言的直觉,但一般会有一些困难。有可能处理器提供高性能计算模式而异常不精确的工作模式。但一般来说,page 相关异常和 ieee 整数运算异常一般都会被精确处理。
- 指令中间状态需要回滚
- 指令执行中修改内存:异常时候保存工作寄存器,之后重新开始
- 隐式的修改状态寄存器:如同追踪寄存器依赖一样追踪潜在的 data hazard
- 长指令(如浮点运算指令,参见多周期指令 )
| Exception Type | Synchronous(和具体代码、数据有关) vs Asynchronous | User Request vs Coerced | User Maskable vs Nonmaskable | within(指令本身引发,需要重启指令) vs between Instructions | Resume vs Terminate |
|---|---|---|---|---|---|
| I/O device request | Asynchronous | Coerced | Nonmaskable | Between | Resume |
| Invoke operating system | Synchronous | User request | Nonmaskable | Between | Resume |
| Tracing instruction execution | Synchronous | User request | User maskable | Between | Resume |
| Breakpoint | Synchronous | User request | User maskable | Between | Resume |
| Integer arithmetic overflow | Synchronous | Coerced | User maskable | Within | Resume |
| Floating-point arithmetic overflow or underflow | Synchronous | Coerced | User maskable | Within | Resume |
| Page fault | Synchronous | Coerced | Nonmaskable | Within | Resume |
| Misaligned memory accesses | Synchronous | Coerced | User maskable | Within | Resume |
| Memory protection violations | Synchronous | Coerced | Nonmaskable | Within | Resume |
| Using undefined instructions | Synchronous | Coerced | Nonmaskable | Within | Terminate |
| Hardware malfunctions | Asynchronous | Coerced | Nonmaskable | Within | Terminate |
| Power failure | Asynchronous | Coerced | Nonmaskable | Within | Terminate |
Pitfall
- 未预料的执行顺序会导致未预料的冲突
- 即使是顺序处理器,浮点指令周期不同,两条指令之间出现异常,连续写同一寄存器而有可能产生 WAW
- 过度设计的流水线会影响整个处理器设计,可能损害性价比
- VAX 系列,流水过深过于复杂导致主频低,而且消耗大量晶体管资源
- 使用优化等级低的代码衡量处理器调度能力
- 现实中代码一般都是
-O2优化的;未优化代码存在大量冗余,不能充分考验处理器的硬件调度能力
- 现实中代码一般都是
- 有时候加面积+不那么智能也很好
- 把做复杂逻辑的晶体管面积直接做成 cache,根本上减少 cache 的延迟
- 有时候更聪明更好
- 高效的分支预测很重要,更低的错误率意味更少的清空流水线
- 对比简单的 g-share 预测器,更好的算法记录 tags,可以避免混淆不同地方的分支预测结果
- 不存在永远可待挖掘的 ILP 的潜力
- 即使采用非常理想的配置,现实中的程序(特别是整数程序)能并行的也是有限的
Fallacy
- 对于同一套指令集的不同版本,容易预测其性能和能耗
- Intel 的 i7 920 和 Atom 230 对比实验,性能差 4 倍,功耗差 10 倍
- 带推断的动态乱序执行有利于性能,但会极大提高功耗
- 更低的 CPI,更快
- 更高的时钟频率,更快
- CPI 和时钟频率乘积共同决定性能,偏废会导致短板效应。
ch 4 Data-Level Parallelism in Vector, SIMD, and GPU Architectures
SIMD
single instruction multiple data
DLP
data level parallelism
Roofline-Model
可以定义计算强度,用来衡量程序内计算部分的占比。只有计算强度高的程序,才更容易被 SIMD/GPU 等加速
arithmetric intensity
每 byte 内存访问对应的浮点运算次数。可用于预测 vector 支持对程序性能的提升
给定的系统,不同计算强度的程序被不同因素限制住。计算强度低的程序,访存多而计算少,内存带宽跟不上,被带宽限制;计算强度高的程序,计算多而访存少,被浮点部件性能限制。因此,表现到图上就是 roofline 形状:随着计算强度增加,程序的 $\text{GFLOP/s}$ 提升;提升到了浮点性能极限时候,再改变计算强度,能实现的 $\text{GFLOP/s}$ 也是一条平行线。
$$ \begin{aligned} \text{Attainable GFLOP/s}=\min( &\text{Peak Memory BW}\times\text{Arithmetic Intensity}, \\ & \text{Peak Floating-Point Perf}) \end{aligned} $$
向量架构
- 向量寄存器:长的寄存器(eg,RV64V,64bit),一次存一个向量,支持不同数据类型(
i8,i16,i32,i64,f16,f32,f64) - 向量功能部件
- 向量访存部件
- 辅助的标量寄存器
dynamic register typing
每个向量寄存器配置不同的数据类型和长度,而不是在指令中区分
- 简化向量指令的实现
- 允许关闭不用的寄存器,扩展使用的寄存器位数
- 不同类型的操作数之间
convoy
一组可以同时执行的向量指令(必须不存在 structural hazard)。其用时为 chime
可以简化的认为,通过 convoy 数目表征向量程序用时。同一个 convoy 里面可以出现 RAW,因为向量的一部分元素在一个部件完成后可以直接前递到其他部件。一个 convoy 会处理多个元素,仍然有很高的并行度。
- RV64V 只允许位置相同的元素进行向量间运算,因此多条流水线可以并行处理各个元素
vl寄存器用于标记长度(必然 $\le \rm{mvl}$,maximum vector length)。可以在运行时动态指定(strip mining),只对vl长度进行处理vector-mask control
用一个 mask 条件执行来完成分支
- 向量功能部件要求更好的访存
- 每个周期允许多个访存
- 支持不连续的访存
- 允许多核间共享内存
stride
对于没有分块缓存的,先按 stride(nonunit strides)预读入向量,将空间不相邻元素转换为逻辑相邻。由于跨 stride 步长加载元素,有可能短时间 GCD 访问同一内存单元,造成阻塞,条件如下$\frac{\text{numbers of banks}}{\text{GCD(stride, number of banks)}}<\text{bank busy time}$
gather-scatter
对索引访存(eg 稀疏矩阵)进行优化,需要额外的索引寄存器,比起其他访存更慢
面向多媒体的 SIMD 扩展
一般不支持 mask registers、gather-scatter 以及 stride 等向量化高级优化手段,一般要求固定的向量长度和类型(从而导致指令集膨胀,每种数据类型对应一条指令),因此向量化程序不容易编写,编译器不容易优化,一般只针对专门的多媒体库(音视频的数据表示一般不需要全长度)或者是手写内嵌汇编。实例有 intel 的 MMX,SSE,AVX(开始支持高级操作)等。SIMD 扩展可能带来历史兼容性的问题。
- 再增加基本运算单元花销小(模式简单,MMX 用原先的 64bit 浮点寄存器支持$8\times 8$-bit 或$4\times 16$-bit 的操作),容易支持
- 比起专门的 vector 架构,添加 SIMD 支持给处理器带来额外的状态,需要在上下文切换时候保存
- vector architecture 需要内存带宽支持发挥最大性能
- 一般的 SIMD 扩展要求内存对齐访问,对于虚拟内存实现方便,不会跨页 page fault
- 向量长度定长,便于加入新的向量操作来支持新的多媒体应用需求
GPU
CUDA
Nvidia 为其 GPU 提供了兼容 C/C++的编程解决方案,CUDA。
- GPU 上运行的函数标识
__device____global__;CPU 上运行的函数标识__host__ - CUDA 变量
__device__,分配在 GPU Memory 上,所有的 multithreaded SIMD Processors 可访问 - 函数调用形式为
name<<<dimGrid, dimBlock>>> (… parameter list…)dimGrid规定 thread block 数目,用blockIdx索引dimBlock规定一个 block 内 thread 数目,用threadIdx索引
| |
CUDA 会编译成 PTX(Parallel Thread Execution)指令集,有如下格式
opcode.type d, a, b, c;
- type 类型,bits/整形/浮点
- d 目标
- a,b,c 源
原先的DAXPY对应的汇编如下
| |
PTX 的所有访存模式都是 gather-scatter。为了加速顺序访问,要求访存遵守 Address Coalescing 的规则,以便合并为块访存。
GPU 使用 mask(编译器和硬件隐性设置,而不是显式有指令设置)和 branch synchronization stack(线程私有,每个条目一个标识符,一个目标地址,一个 mask)显式执行分支。预先算出 mask,压栈,使用 IF-THEN-ELSE 模式执行(要么执行 THEN 要么执行分支 ELSE)。除非全 0/1,会跳过其中一个分支,否则分支永远带来额外开销。因为 GPU Thread 之间强依赖,同一个 Thread Block 内的 lane 要么执行相同的指令,要么闲置,不能像操作系统线程那样分别执行。该机制同样适用于向量长度不是整数倍情况。
对于以下代码,对应 PTX 汇编
| |
| |
层次结构
代码组织成 3 层:
- Grid:一段并行的任务
- Thread Block:在一个处理器(Streaming Multiprocessor)上并行的代码段,共用 local memory 和一组寄存器(数目有限)
- Thread:串行执行的代码段,寄存器有上限的从共用寄存器按需分配
两层调度
- Thread Block Scheduler:把 Gird 或多个 Thread Block 在处理器之间调度
- SIMD Thread Scheduler:单个 Thread Block 在处理器内调度,内部类似 SIMD 指令,彼此独立,可以使用 scoreboard 乱序追踪指令以掩盖访存延迟
存储层次
- private memory:在片外 DRAM 上,thread 私有一小部分
- local memory:片内的高带宽低延迟存储,对 multiprocessor 内私有,但如果多个 Thread Block 同时执行,不能在之间共享状态
- GPU memory:片外 DRAM 上,host 能读写
对照
| 方面 | vector architecture | GPU |
|---|---|---|
| 隐藏访存延迟 | 深流水线,不同流水级之间重叠执行 | 多 thread |
| 分支 | 显式设置 mask | 硬件和汇编器隐式设置 mask 和 stack |
| 控制 | 专门的 control processor:调度、算标量、算地址 | 只有 scheduler,自己计算地址(之后 Address Coalescing)、算标量 |
| 标量计算 | 专门的 scalar 部分,片上网络连接 | 靠 CPU,PCIe 总线连接,开销更大 |
| 并行部件 | lane 数目少,寄存器少 | lane 很多,multiprocessor 也多,寄存器空间大 |
| More Descriptive Name used in this Book | Closest old term outside of GPUs | Official CUDA/ NVIDIA Term | Book Definition and OpenCL Terms | Official CUDA/NVIDIA Definition |
|---|---|---|---|---|
| Vectorizable Loop | Vectorizable Loop | Grid | A vectorizable loop, executed on the GPU, made up of 1 or more “Thread Blocks” (or bodies of vectorized loop) that can execute in parallel.OpenCL name is “index range.” | A Grid is an array of Thread Blocks that can execute concurrently, equentially, or a mixture. |
| Body of Vectorized Loop | Body of a (Strip-Mined) Vectorized Loop | Thread Block | A vectorized loop executed on a “Streaming Multiprocessor” (multithreaded SIMD processor), made up of 1 or more “Warps” (or threads of SIMD instructions). These “Warps” (SIMD Threads) can communicate via “Shared Memory” (Local Memory). OpenCL calls a thread block a “work group.” | A Thread Block is an array of CUDA threads that execute concurrently together and can cooperate and communicate via Shared Memory and barrier synchronization. A Thread Block has a Thread Block ID within its Grid. |
| Sequence of SIMD Lane Operations | One iteration of a Scalar Loop | CUDA Thread | A vertical cut of a “Warp” (or thread of SIMD instructions) corresponding to one element executed by one “Thread Processor” (or SIMD lane). Result is stored depending on mask. OpenCL calls a CUDA thread a “work item.” | A CUDA Thread is a lightweight thread that executes a sequential program and can cooperate with other CUDA threads executing in the same Thread Block. A CUDA thread has a thread ID within its Thread Block. |
| A Thread of SIMD Instructions | Thread of Vector Instructions | Warp | A traditional thread, but it contains just SIMD instructions that are executed on a “Streaming Multiprocessor” (multithreaded SIMD processor). Results stored depending on a per element mask. | A Warp is a set of parallel CUDA Threads (e.g., 32) that execute the same instruction together in a multithreaded SIMT/SIMD processor. |
| SIMD Instruction | Vector Instruction | PTX Instruction | A single SIMD instruction executed across the “Thread Processors” (SIMD lanes). | A PTX instruction specifies an instruction executed by a CUDA Thread. |
| Multithreaded SIMD Processor | (Multithreaded) Vector Processor | Streaming Multiprocessor | Multithreaded SIMD processor that executes “Warps” (thread of SIMD instructions), independent of other SIMD processors. OpenCL calls it a “Compute Unit.” However, CUDA programmer writes program for one lane rather than for a “vector” of multiple SIMD lanes. | A Streaming Multiprocessor (SM) is a multithreaded SIMT/SIMD processor that executes Warps of CUDA Threads. A SIMT program specifies the execution of one CUDA thread, rather than a vector of multiple SIMD lanes. |
| Thread Block Scheduler | Scalar Processor | Giga Thread Engine | Assigns multiple “Thread Blocks” (or body of vectorized loop) to “Streaming Multiprocessors” (multithreaded SIMD processors). | Distributes and schedules Thread Blocks of a Grid to Streaming Multiprocessors as resources become available. |
| SIMD Thread Scheduler | Thread Scheduler in a Multithread CPU | Warp Scheduler | Hardware unit that schedules and issues “Warps” (threads of SIMD instructions) when they are ready to execute; includes a scoreboard to track “Warp” (SIMD thread) execution. | A Warp Scheduler in a Streaming Multiprocessor schedules Warps for execution when their next instruction is ready to execute. |
| SIMD Lane | Vector Lane | Thread Processor | Hardware SIMD Lane that executes the operations in a “Warp” (thread of SIMD instructions) on a single element. Results stored depending on mask. OpenCL calls it a “Processing Element.” | A Thread Processor is a datapath and register file portion of a Streaming Multiprocessor that executes operations for one or more lanes of a Warp. |
| GPU Memory | Main Memory | Global memory | DRAM memory accessible by all “Streaming Multiprocessors” (or multithreaded SIMD processors) in a GPU. OpenCL calls it “Global Memory.” | Global Memory is accessible by all CUDA Threads in any Thread Block in any Grid. Implemented as a region of DRAM, and may be cached. |
| Private Memory | Stack / Thread Local Storage(OS) | Local Memory | Portion of DRAM memory private to each “Thread Processor” (SIMD lane). OpenCL calls it “Private Memory.” | Private “thread-local” memory for a CUDA Thread. Implemented as a cached region of DRAM. |
| Local Memory | Local Memory | Shared Memory | Fast local SRAM for one “Streaming Multiprocessor” (multithreaded SIMD processor), unavailable to other Streaming Multiprocessors. OpenCL calls it “Local Memory.” | Fast SRAM memory shared by the CUDA Threads composing a Thread Block, and private to that Thread Block. Used for communication among CUDA Threads in a Thread Block at barrier synchronization points. |
| SIMD Lane Registers | Vector Lane Registers | Registers | Registers in a single “Thread Processor” (SIMD lane) allocated across full “Thread Block” (or body of vectorized loop). | Private registers for a CUDA Thread. Implemented as multithreaded register file for certain lanes of several warps for each thread processor. |
Loop-level parallelism 改进
在源码(或者接近源码级别检测)
loop-carried dependence
循环依赖于之前的结果
| |
依赖检测
Affine
当一维数组的索引可以写成 $a\times i +b$的形式,当中$a,b$为常数,$i$为循环变量,索引可认为 affine。当多维数组中每一维的索引满足 affine,索引可认为 affine
一般的稀疏访问
x[y[i]],一般不是 affine 的
对应 affine 的索引,同一个数组分别按照$a\times i +b$ 、 $c\times i+d$进行索引,$i\in [m,n]$时,有依赖关系
- 两个索引$m\le j\le n,m\le k \le n$
- 存在$a\times j+b=c\times k+d$的访问
可以简化的使用 GCD(最大公因数)法检测。只保证充分性;因为未考虑边界条件,所以不满足必要性。事实上,检测依赖属于 $\mathcal{NP}-Complete$ 问题
$$(d-b)\mod\rm{GCD}(c,a)=0$$
另一种依赖消除
| |
Fallacy
- GPU 和 CPU 分离不好
- 分离主内存和 GPU 内存有劣势(eg,需要专门的内存复制
cudaMemcpy()) - PTX 指令集和硬件可以根据环境需求动态增减特性,而且不影响 CPU 端的体系结构
- 同时 GPU 端也和 CPU 端的体系结构变动解耦
- 分离主内存和 GPU 内存有劣势(eg,需要专门的内存复制
- 不给 vector architecture 提供足够的访存带宽
- 记住roofline 模型,足够的内存带宽才能有足够数据喂饱计算能力
- 如果 GPU 访存性能不好,无脑增加 thread 数目
- thread 之间需要能够访存融合,否则会导致单独的大量访存反而影响性能
- thread 本身也需要足够好的访存局部性
Pitfall
- 忽略启动开销来对比 vector architecture 之间的峰值性能
- 早期向量架构启动很慢,短向量(eg,$\le 100$)还不如直接用标量处理器
- 只关注 vector architecture 的向量性能,不关注标量性能
- 注意 Amdahl 定律,标量性能很有用(eg,strip mining,不满长的向量的下标索引)
- 增加 SIMD lane 数目同时,需要响应提升标量部分性能
ch 5 Thread-Level Parallelism
本章主要关注 TLP(Thread-Level Parallelism),通过 MIMD 形式的并行。注意,SMP 和 NUMA 的地址空间都是统一的,都可以通过 shared memory 共享和通信,而不是只能通过网络连接。但是,发掘 TLP 有很多困难:
- Amdahl 定律下,程序并行部分有限
- 共享内存访问延迟很高
- Dennard scaling 失效,芯片有功耗限制,不能无限制堆核
Dennard scaling
在晶体管特征尺寸缩小同时,供应电压降低。使得单位面积的功耗近似不变
SMP
symmetric (shared-memory) multiprocessors,或者是 centralized shared-memory multiprocessors。所有核平等共享一个中心的内存
UMA
uniform memory access (UMA) multiprocessors
NUMA
Nonuniform Memory Access。对内存的访问时间不是相同的
NUCA
Nonuniform Cache Access。对 cache 的访问时间不是相同的
DSM
distributed shared memory,为了支持更多核/处理器,物理上划分内存为多个
Memory Consistency 模型
对于程序员,主要依赖可靠的并行库提供的同步操作来保证正确性,因为为了确保底层体系结构确实实现同步
synchronized/data-race-free
对于程序,所有共享部分访问都被同步操作排序
最简单也直观的 Memory Consistency 模型是 Sequential Consistency。但是该模型性能不好。
Sequential Consistency
(执行结果就像,可以实际上不是)每个处理器的访存保持顺序,处理器之间访存可以任意交叉
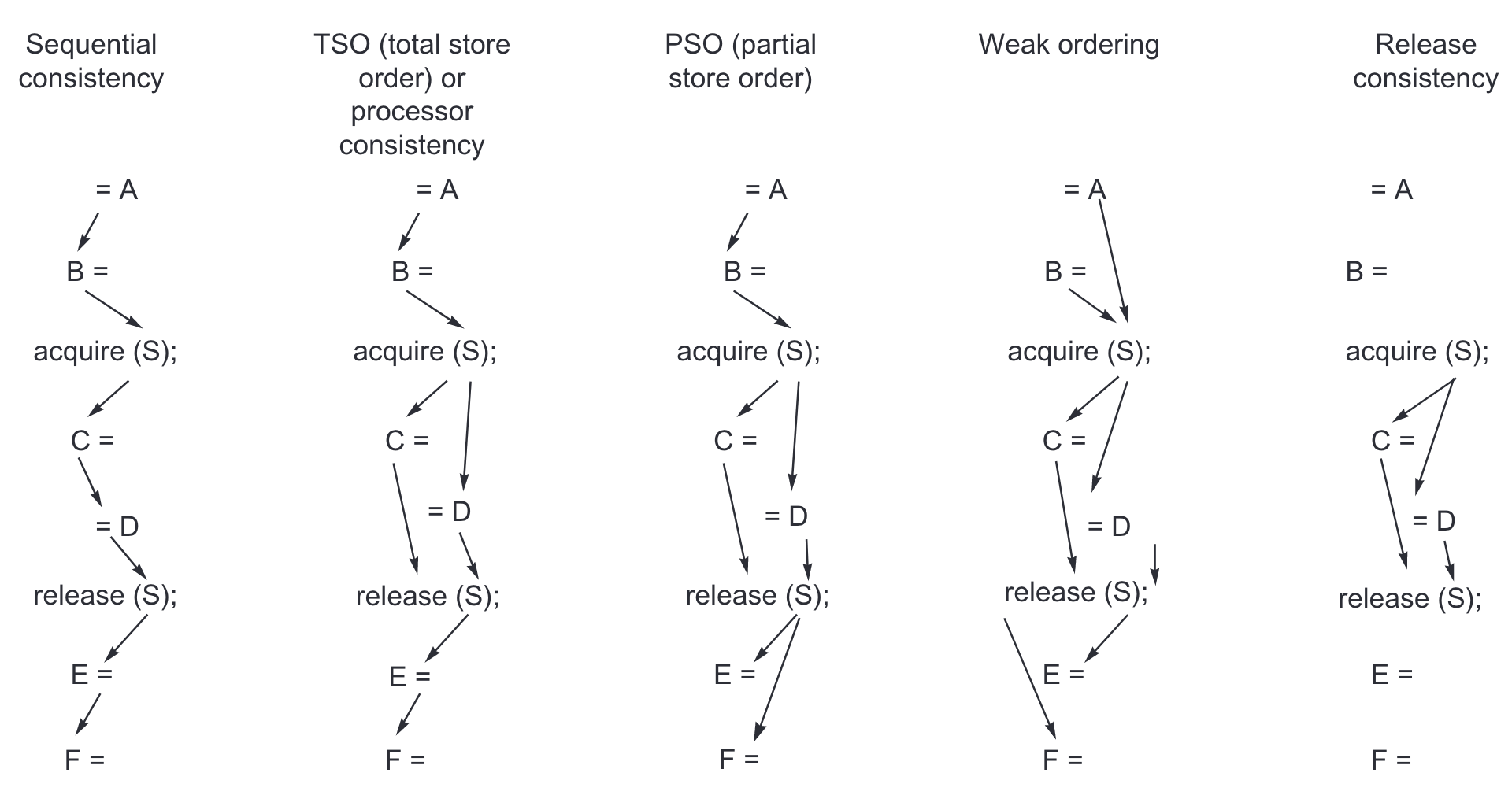
为了提高性能,可以放松访存一致性的要求。使用$\to$ 表示顺序,不同的一致性模型对不同操作之间的顺序有不同的要求。
- $R$为一般的读操作
- $W$为一般的写操作
- $S$为任意的同步操作
- $S_A$为取得的同步操作(类似
lock()) - $S_R$为释放的同步操作(类似
unlock())
| Model | Used in | Ordinary orderings | Synchronization orderings |
|---|---|---|---|
| Sequential consistency | Most machines as an optional mode | $\mathrm{R\to R,R\to W}$,$\mathrm{W\to R,W\to W}$ | $\mathrm{S\to W, S\to R, R\to S, W\to S, S\to S}$ |
| Total store order or processor consistency | IBMS/370, DEC VAX, SPARC | $\mathrm{R\to R,R\to W}$,$\mathrm{W\to W}$ | $\mathrm{S\to W, S\to R, R\to S, W\to S, S\to S}$ |
| Partial store order | SPARC | $\mathrm{R\to R,R\to W}$ | $\mathrm{S\to W, S\to R, R\to S, W\to S, S\to S}$ |
| Weak ordering | PowerPC | $\mathrm{S\to W, S\to R, R\to S, W\to S, S\to S}$ | |
| Release consistency | MIPS, RISC V, Armv8, C, and C++ specifications | $\mathrm{S_A\to W, S_A\to R, R\to S_R, W\to S_R}$,$\mathrm{ S_A\to S_A, S_A\to S_R, S_R\to S_A, S_R\to S_R}$ |
Centralized Shared-Memory Architectures
coherent 的内存
- P 写了位置 X,在没有其他处理器写位置 X 时,P 再读位置 X,读到自己写的值
- P 写完位置 X,Q 在足够间隔且没有其他写的情况下读位置 X,应该能看到 P 写的值
write serialization
写同一位置的顺序是一致的:P 先写 Q 后写对于所有处理器都是一样的
Coherence 和 Consistency(参见上面部分 ) 侧重点不一样。Coherence 规定同一位置的读写行为;Consistency 规定涉及其他位置访存时候的读写行为。维护 cache coherence 有两种方向的协议:Directory based 和Snooping
Snooping
Snooping
基于侦听。每个缓存共享内存的处理器自己追踪状态变化。可以通过比如侦听总线上广播的形式
有两种主要的 snooping 的变种
write invalidate
处理器在能写共享部分之前,先独占的拥有其。因此,每次写都会使得其他处理器上副本失效
write update/write broadcast
根据写的结果,广播更新其他副本
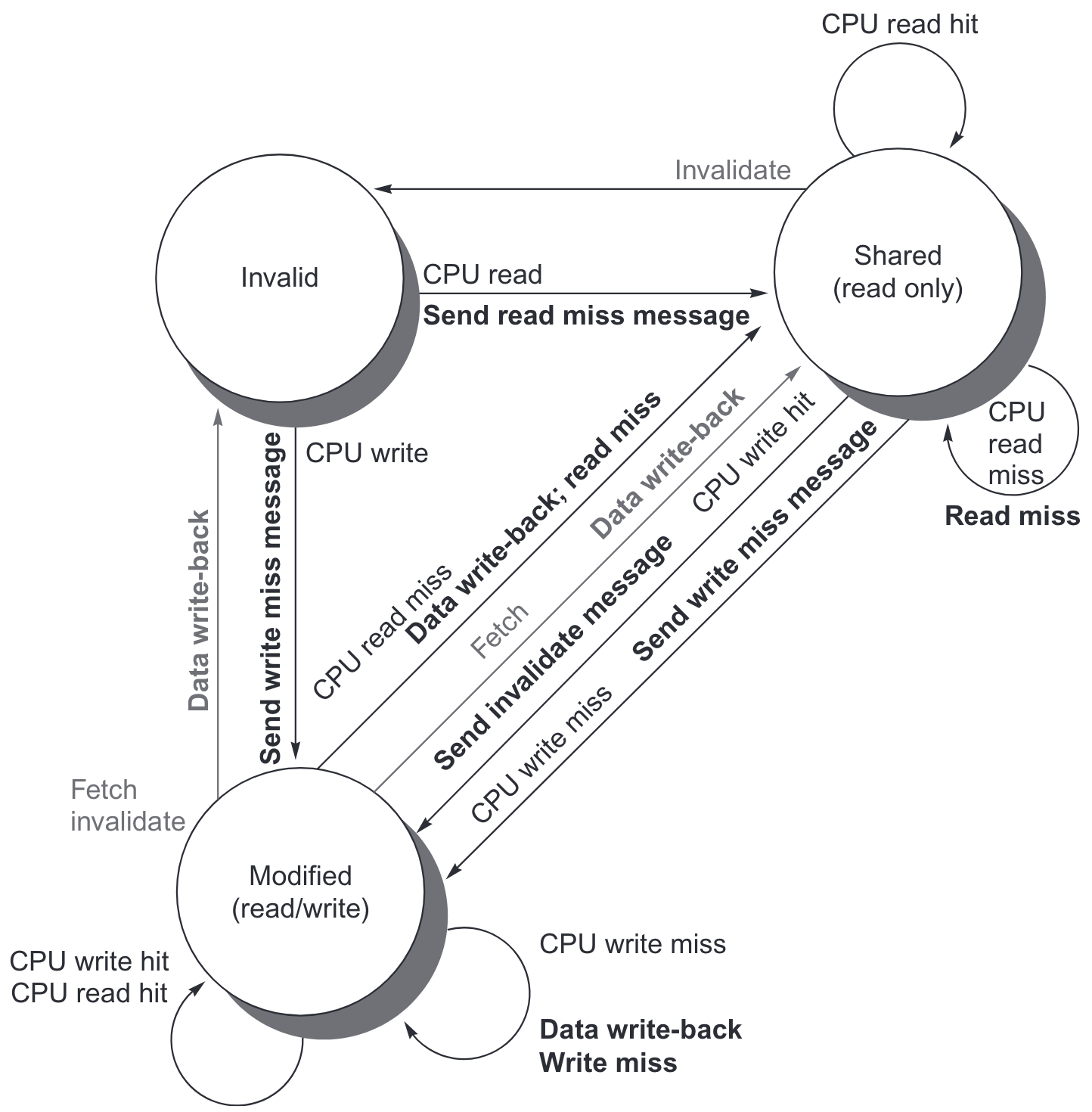
一般的 Snooping 协议实现都是每个处理器和 cache 维护一个有限状态机。对于一个简化版协议,可以认为一共有 3 种状态,Invalid,Shared 和 Modified,这也被称为 MSI 协议。对于使用 write invalidate,write back cache 的 Snooping 协议,cache 状态转移图表示如下。具体细节有表格。注意,这里假定各操作是原子的。如果是单一的中心化总线,可以把总线的获取和释放用于同步。多总线可以指定每条总线负责一个范围的共享内存。
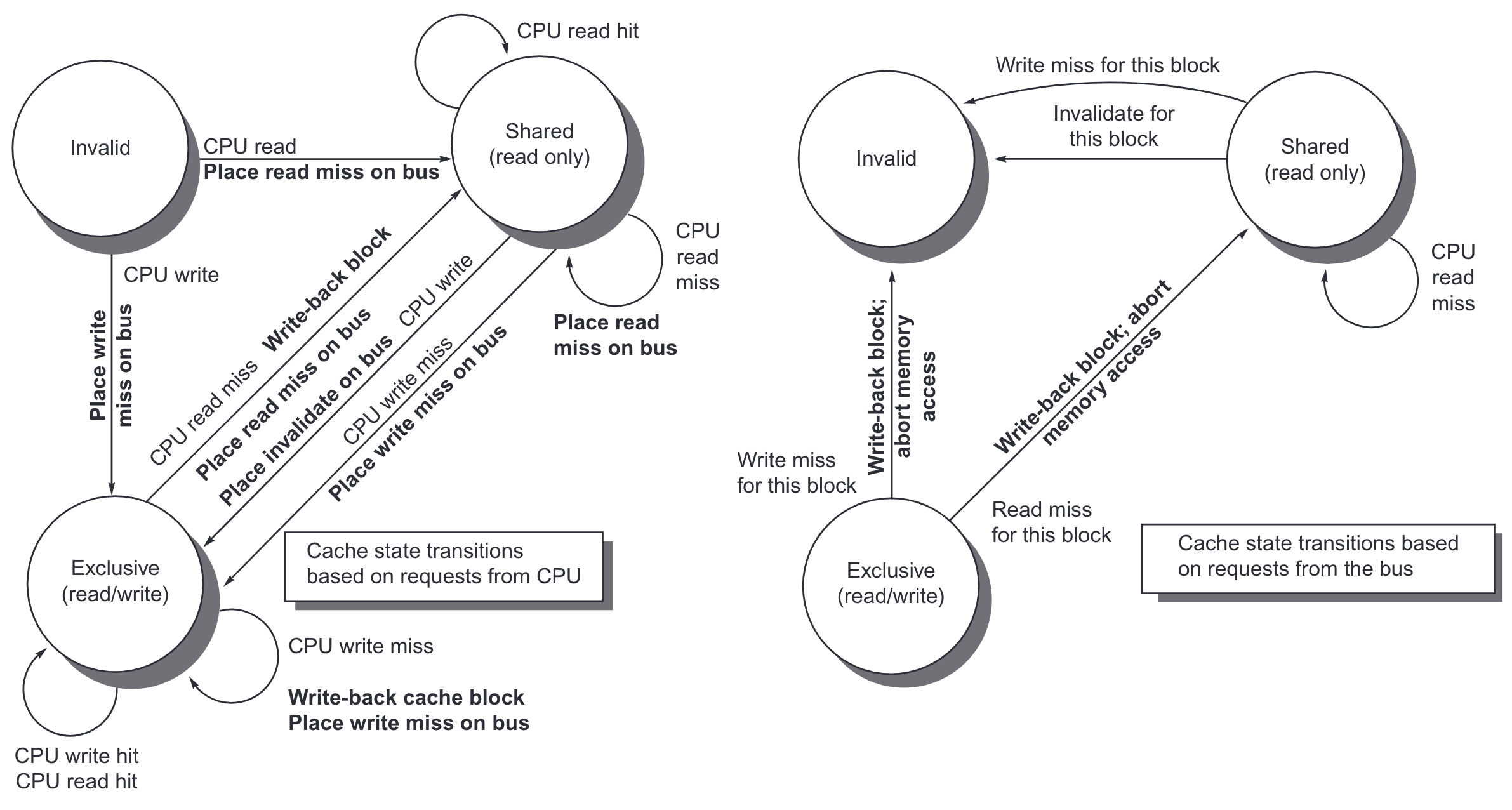
| 请求 | 源 | 对应 cache 块状态 | cache 行动 | 解释 |
|---|---|---|---|---|
| Read hit | Processor | Shared/modified | 正常命中 | 把数据读进 local cache |
| Read miss | Processor | Invalid | 正常缺失 | 总线上广播 read miss |
| Read miss | Processor | Shared | 替换 | 共享地址的缺失: 总线上广播 read miss |
| Read miss | Processor | Modified | 替换 | 共享地址的缺失: 先写回,再在总线上广播 read miss |
| Write hit | Processor | Modified | 正常命中 | 向 local cache 写数据 |
| Write hit | Processor | Shared | Coherence | 总线上广播 invalidate,因为不会去 fetch 数据,只是改变数据的状态,这一般被称为 upgrade 或者 ownership misses |
| Write miss | Processor | Invalid | 正常缺失 | 在总线上广播 write miss |
| Write miss | Processor | Shared | 替换 | 共享地址的缺失: 在总线上广播 write miss |
| Write miss | Processor | Modified | 替换 | 共享地址的缺失:先写回;然后在总线上广播 write miss |
| Read miss | Bus | Shared | 无需行动 | 用自己的 cache 或者内存的内容去解决其他处理器的 read miss. |
| Read miss | Bus | Modified | 维护一致性 | 其他处理器尝试读共享数据: 把自己的 cache 块广播到总线, 写回,然后把自己数据状态改成 shared |
| Invalidate | Bus | Shared | 维护一致性 | 其他处理器尝试写共享数据; 把自己数据变为 invalidate 态 |
| Write miss | Bus | Shared | 维护一致性 | 其他处理器尝试读共享数据: 把自己数据变为 invalidate 态 |
| Write miss | Bus | Modified | 维护一致性 | 其他处理器尝试写独占的数据:写回,然后把自己数据变为 invalidate 态 |
除了最基本的 MSI 协议,还可以拓展更多状态。比如
- MESI:多了 Exclusive。E 状态表示只有一个处理器有副本,而且是 clean 的,写的时候不需要广播 invalidate 消息,因此不需要再次访问总线而有开销;当其他处理器对其 read miss,就会转为 Shared 态。可以通过 dirty 位来区别 Exclusive 和 Modified 态
- MESIF:多了 Exclusive 和 Forward,F 用来在分布式内存环境下,指定某个(共享中的)处理器处理请求
- MOESI:多了 Exclusive 和 Owned。如果其他处理器需要读 Modified 的数据,原先处理器状态转为 Owned 态,而先不写回内存。O 态表示内存数据不是最新的,该数据相关的 miss 由仅有一个的 O 态处理器负责提供(eg,AMD Opteron)
snooping 协议可能有以下问题导致可拓展性不好
- 总线负担大
- cache 负担大,需要检查每个 invalidate 信号
coherence miss
由于缓存一致性协议导致的 cache miss
- true sharing:真正的缺失,比如其他处理器要求独占之后的缺失
- false sharing:同一个 cache line 当中,实际没有共享数据被共享部分涉及而产生的缺失
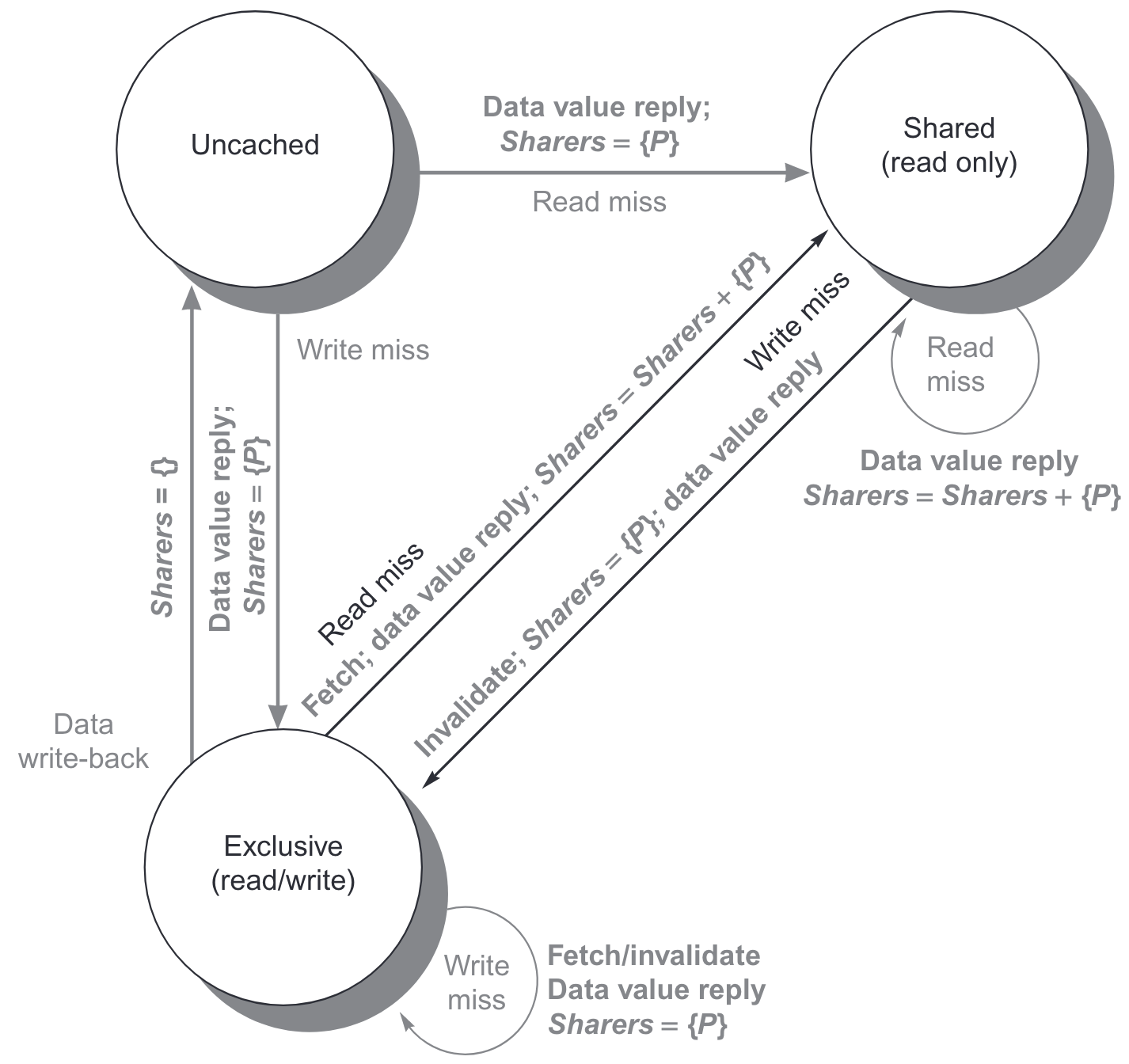
Directory based
Directory based
基于目录。共享内存的状态被一块专门的目录(directory)管理,在 SMP 中维护一个中心化的目录,而在 NUMA 中目录也要分布开
简单的目录协议中,除了单独的 cache 块有 MSI3 种状态,目录本身有 3 种状态。可以使用位图,每个位表示某个处理器是否持有副本(eg, intel i7)。NUMA 架构里,目录和对应管理的共享存储可以放在一起,保证分布式的目录可以被唯一的确定和找到。
- Shared:至少一个节点有副本,而且内存里是最新值
- Uncached:没有节点有副本
- Modified:有且只有一个节点有最新的副本,内存里是旧的值
和 snooping 协议里广播和侦听总线不同,目录协议直接对特定节点发消息。这里假定消息收发是 FIFO 的,消息之间处理是原子的。为了方便,节点做如下区分
- local node:发送请求的节点
- home node:请求地址对应内存和目录的管理节点
- remote node:拥有数据副本的节点
| 消息类型 | 源 | 目的 | 内容 | 功能 |
|---|---|---|---|---|
| Read miss | Local cache | Home directory | P, A | 节点 P 读地址 A 出现 read miss,请求数据,并把节点 P 设置为读共享 |
| Write miss | Local cache | Home directory | P, A | 节点 P 写地址 A 出现 write miss,请求数据,并把节点 P 设置为独占 |
| Invalidate | Local cache | Home directory | A | 请求共享地址 A 的节点发送 invalidate(不是真的发了 invalidate,和下一项区分) |
| Invalidate | Home directory | Remote cache | A | 把地址 A 的数据副本置 invalid |
| Fetch | Home directory | Remote cache | A | 请求地址 A 的数据,更新 home 节点的数据和目录,并把持有地址 A 数据的节点置为共享态 |
| Fetch/ invalidate | Home directory | Remote cache | A | 请求地址 A 的数据,更新 home 节点的数据和目录,并把持有地址 A 数据的节点置为 invalid |
| Data value reply | Home directory | Local cache | D | 从 home 内存取值发出去 |
| Data writeback | Remote cache | Home directory | A, D | 把地址 A 的数据写回到 home 内存 |
对于一个单独的 cache 块,其状态转移图非常类似 snooping 协议(把来自 local 的消息标黑,来自 home 的消息标灰)
而目录对于 cache 块和消息的也有状态转移图(注意,对于目录而言,所有改变都是因为有外部的请求,所以全部标灰)
同步操作
常见的硬件同步原语有
- atomic-echange:原子的交换
- fetch-and-add(FA):原子加,共识数小,但是简单,不容易竞争
- compare-and-set (CAS):比较预期值和内存变量,相等时候改为新传入的值,反之不修改,返回执行之后的内存变量值,会有 ABA 问题
- load-reserved 和 store-conditional:成对使用,在
lr预定一个地址到sc写同一个地址之间,如果有其他的写,sc会返回非零错误值,天然免疫 ABA 问题,但是多核容易导致竞争抖动
可以用lr,sc来实现其他同步原语效果
| |
进一步的可以用同步原语构件自旋锁(spin-lock)
| |
lr,sc原语有效的分离了变量的读写,可以减少总线负担。直接使用lr,sc实现自旋锁如下
| |
Fallacy
- Amdahl 定律对并行计算不适用
- 简单的放缩基准数据集(weak scaling),使得程序串行规模部分几乎不变,只有并行部分放大,会导致虚假的加速比
- 需要合理衡量 true speedup 时候对串行和并行所用的数据集
- 多处理器只有实现完美的线性加速比才成本上合算
- 执行时间短(现实中一般只会关注任务用时,而不是每个处理器时间加和)是公认的并行的优势
- 成本不是简单的正比于处理器数目,还有内存,硬盘,多核芯片等因素
Pitfall
- 衡量多核性能时候,只考虑执行时间的加速比
- 加速比对比对象:相对低端芯片加速比很大并不一定意味着性能好;对于浮点计算密集程序,如果没有专门硬件部件,或许实现可以接近线性加速比,但性能还是很差
- 注意区分 relative speedup 和 true speedup,应该对比并行最优的算法和串行的最优算法
- 没有发展专门对多处理器架构优化的软件
- eg:在使用锁管理页表的 os 上,即使是完美并行的程序,依然会被页分配制约
ch A Instruction Set Principles
ISA 特性
对于 ISA 设计,其有如下一些考虑:
- 指令集类型
- 栈
- 累加器
- 寄存器-内存
- 寄存器-寄存器/load-store
- 地址访问:对齐、不对齐
- 寻址模式
- 立即数
3 - 寄存器
Regs[R4] - 寄存器访存
Mem[Regs[R4]] - 寄存器+偏移访存
Mem[Regs[R4]+10] - 寄存器+寄存器访存
Mem[Regs[R3]+Regs[R4]] - 立即数访存
Mem[1001] - PC 相关
pc - 寄存器间接访存
Mem[Mem[Regs[R4]]] - 自增自减
Mem[Regs[R2]+=d] - 寄存器+寄存器倍增访存
Mem[Regs[R2]+Regs[R3]*d]
- 立即数
- 操作数类型:
- 整型
u8,i8,u16,i16,u32,i32,u64,i64 - 浮点数
f32,f64 - 拓展浮点数 80 位
- 整型
- 指令类型
- 运算和逻辑
- 访存
- 控制
- 系统特权有关
- 浮点数指令
- decimal 指令
- 字符串指令
- 图像指令
- SIMD
- 控制流指令
- 无条件跳转
- 条件转移
- 函数调用
- 函数 return
- ISA 编码:
- 寄存器数目:对应编译器分配,解依赖,编码长度
- 定长,变长
- 寄存器编码位置固定/不固定
编译器优化
| 编译器层次 | 依赖 | 功能 |
|---|---|---|
| front end per language | 语言相关,和机器无关 | 语言翻译成通用 intermediate 形式 |
| high-level optimizations | 语言相关,基本和机器无关 | eg,循环展开,函数内连 |
| global optimizer | 基本语言无关,和机器有关(寄存器数目和类型) | 优化和寄存器分配 |
| code generator | 语言无关,机器相关 | 具体的机器特定优化和指令选择 |
- 寄存器数目$\ge 16$个以方便启发性的 group coloring 的寄存器分配算法(本质是个$\mathcal{NP}$问题,只有近似线性的启发式算法)
- 保证常见场景优化+罕见场景正确
- 操作,数据类型和寻址 3 者可以正交组合
- 提供 primitive 原语,而不是方案,防止过于适配高层语言
- 简化 trade-off 的选择
- 保证编译期常量能直接绑定到指令
SIMD 指令基本上违背所有原则(vec 寄存器数目少,寻址模式过于简单,vec 类型不常见 etc.)。因此 SIMD 一般只有用在人工编写的底层库
ISA 统计和对应的 RISC-V 设计
Fallacy
- 存在一个典型程序:不同程序对 ISA 的使用差异巨大
- 有缺陷的 ISA 不能成功(80x86)
- 存在完美的体系结构
- trade-off 永存
- 不同技术和时代强调目标不同
Pitfall
- 设计一个高层次指令来支持高层语言的结构
- semantic gap:过于复杂,功能过剩,或者是对于其他语言其约定有差异
- 设计 ISA 时候不考虑编译器优化
- 编译器优化等级对于体积优化和性能优化结果差异很大